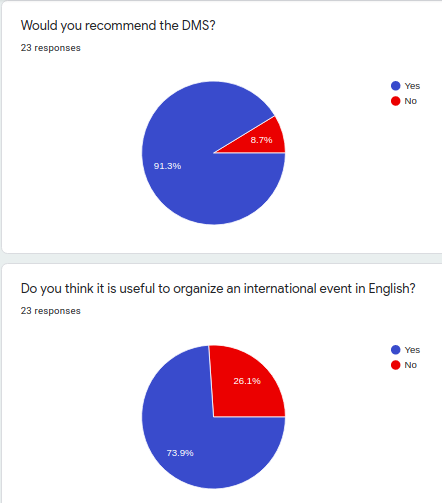
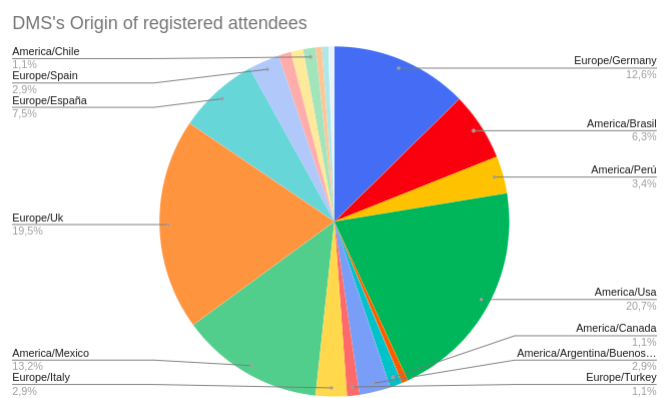
Algunas reflexiones sobre lo que está pasando dentro de las empresas en los últimos años y como algunas de ellas están enfocando las actividades para el 2022. Algunas de estas reflexiones y retos serán parte del contenido de las mesas redonda de la edición 2022 del Data Management Summit
El fin de año conlleva reflexionar sobre lo que se ha visto en el 2021 para lanzarse al vacío del 2022. El vacío porque normalmente “la vida tiene muchas más fantasías que nosotros” y el mundo empresarial está en una encrucijada muy importante. La pandemia ha supuesto la completa revisión de los procesos de trabajo distribuidos y ha sido un acelerador brutal del mundo de los datos. Hace años ya decía “no existe mi puesto” ahora existe mi lugar dentro de una organización que puede ser incluso virtual. Hace años publiqué un libro titulado “Downshifting, Decrecimiento y Empresa Desestructurada” y leerlo ahora da bastante risa porque muchas de estas “premoniciones” se han materializado.
Todo gira alrededor del Dato…
Y aquella empresa que aún no lo ha entendido está muerta o agonizando. El dato es un activo primordial y da exactamente igual donde se trabaja. En una corporación, en un rascacielo del centro de Madrid o en mi casita de Menorca. Los profesionales se están librando del “curro” y empiezan a vivir de “proyectos”. El mundo del trabajo es dinámico y tus conocimientos de hoy no sirven para lo que viene mañana. Los datos fluyen desde que nos levantamos hasta el último de nuestros días. Muchos de nosotros ni siquiera sabemos cuántos GB generamos cada día. Es más fácil saber cuantos KW gastamos (y las facturas de las eléctricas son bien complicadas) que cuantos datos hemos estado generando, no solo en el trabajo sino en nuestro dia a dia.
Pagar por datos
La famosa frase “si es gratis tu eres el producto y no el cliente” es la que mejor define todo esto. Pero.. ¿Porque la industria, con la excusa de generar mi bienestar se queda prácticamente con todo lo que hago? En el futuro las grandes empresas se encontrarán en el medio de dos gigantes: la ética del dato y las nuevas regulaciones en materia de privacidad. Ahora no ha existido una conciencia global sobre lo que supone la cesión de tus datos pero esto va a cambiar en los próximos años. En el 2022 empezaremos a ver un nuevo fenómeno, las empresas van a ofrecer algo más a cambio, para el uso de tus datos.
Alguien ha empezado a cuestionarse todo esto ya hace un tiempo. En su libro ‘¿Quién controla el futuro?‘, de 2013, Jaron Lanier, un personaje que parece salido de Matrix, se fijó en aquellas personas que, haciendo traducciones, ayudaron a Google a perfeccionar su traductor. Ninguno de ellos vio un euro por su trabajo, evidentemente, pero el buscador se benefició, tanto por el trabajo gratuito como por la mayor visibilidad de sus anuncios.
“Lanier postula que la clase media está cada vez más marginada de la economía en línea. Al convencer a los usuarios de entregar información valiosa sobre sí mismos a cambio de servicios gratuitos, las compañías pueden acumular gran cantidad de datos prácticamente sin costo alguno. Lanier llama a estas empresas «servidores sirena», en alusión a las sirenas de Ulises. En lugar de pagar a cada individuo por su contribución a la base de datos, los servidores sirena concentran la riqueza en manos de los pocos que controlan los centros de datos.” (Fuente Wikipedia)
A parte iniciativas esporádicas como Datum oh Kubik Data más bien relacionada al advertising puro vamos a ver a partir del próximo año muchas empresas que están dispuestas a pagar para que nuestros datos personales y biométricos puedan ser almacenados en sus servidores.
Come cambia el Gobierno del Dato con el nuevo paradigma de la banca abierta
El nuevo entorno del Open Banking está transformando el mundo de la banca debido a un nuevo paradigma en el que los servicios financieros operan en un ecosistema completamente digitalizado. Esto ha conllevado a la completa reinvención de las prácticas y los procesos de los modelos bancarios tradicionales. Un cambio epocal hacia el Open Business y la economía basada en la completa interoperabilidad y las APIs, consecuencia, en parte, de las nuevas regulaciones como PSD2. El cambio de paradigma va a generar nuevas formas de enfocar el gobierno de datos siempre más ligado a la completa trazabilidad de los procesos. No solo roles, definiciones y metadatos sino también procesos materializados en el tiempo para satisfacer las necesidades regulatorias.
¿Cómo acelerar la adopción de Open Linked Data en el mundo de la administración pública?
Si es verdad que Open Data es el movimiento digital al que están adhiriendo paulatinamente gobiernos e instituciones de todo el mundo su adopción sigue siendo difícil. Se lanzan experimentos y portales de datos abiertos pero sin duda el punto de inflexión es el lanzamiento de las iniciativas comunitarias como el Data Governance Act: La UE está trabajando para reforzar diversos mecanismos de intercambio de datos. El objetivo es fomentar la disponibilidad de datos que puedan utilizarse para impulsar aplicaciones y soluciones avanzadas en inteligencia artificial, medicina personalizada, movilidad ecológica, fabricación inteligente y otros muchos ámbitos.
Los Estados miembros han acordado un mandato de negociación sobre una propuesta de Ley de Gobernanza de Datos (DGA). La Ley trataría de establecer mecanismos sólidos para facilitar la reutilización de determinadas categorías de datos protegidos del sector público, aumentar la confianza en los servicios de intermediación de datos y promover el altruismo de datos en toda la UE.
Además, la DGA prohíbe vincular los servicios de intermediación con otros servicios como el almacenamiento en la nube o la analítica empresarial, servicios que están excluidos del ámbito de aplicación de la DGA. Esta medida contra la vinculación pretende evitar que las grandes plataformas tecnológicas creen un bloqueo comercial que pueda perjudicar a los competidores más pequeños.
Si saber cómo se mueven los usuarios en el metro de Madrid puede ser útil para reforzar el servicio público, el mismo dato en mano de cualquier empresa cuyo fin (y faltaría más) es el beneficio propio y de sus accionistas no es la misma cosa. Sin embargo regalamos datos continuamente para ver gatitos y delante de una pandemia no queremos colaborar. Almacenamos continuamente datos obsoletos y sin ningún sentido en una especie de síndrome de diogene digital que no cesa debido que el almacenamiento ya no es un coste tan importante. El problema es que este mismo comportamiento se hace en las empresas que no entienden que es mejor tener pocos datos de calidad que mucho sin ningún sentido, no existe algoritmo que puede ordenar y extraer conclusiones certeras de un dato sin sentido. Por esto los científicos de datos se frustran cada día limpiando datos en vez de entenderlo.
La convergencia de los diferentes modelos de calidad de datos
Sin datos de calidad es imposible tomar decisiones. Existen diferentes modelos y marcos de trabajo, desde DAMA hasta ISO. ¿Cómo medir la calidad de los datos, cómo gestionar los procesos de calidad de forma automática? ¿Cómo evitar las corrupciones de los Data Lakes? ¿Por qué no conseguimos que la calidad de los datos pueda ser un proceso horizontal dentro de la empresa? Esencialmente porque somos perezosos, desde quien atiende las llamadas en un call center hasta quien diseña el proceso de las mismas.
Los procesos de enriquecimiento son el valor de la calidad, pero ¿cómo evitar el fenómeno garbage-in garbage-out? ¿Qué hacer con tantos datos de baja calidad?
Normalmente nos encontramos con estos inconvenientes: datos erróneos que no se corrigen, sino que se vuelven a crear, además los mismos datos son introducidos en diferentes sistemas, registros creados con valores erróneos o ausentes, falta de coincidencia entre los datos creados en diferentes sistemas, lo que hace que se tenga que hacer un trabajo adicional en fases posteriores, datos erróneos creados durante la transacción, lo que provoca una acción posterior de corrección o adición de datos, problemas de latencia entre la creación de los datos maestros y los de las transacciones y su consumo por parte de las aplicaciones de informes y transacciones posteriores
La gran pregunta quizá sea: ¿Cómo convencer a las empresas de que el ciclo de vida de la calidad de los datos incluye la muerte de los mismos? El GDPR lo instruye… pero ¿alguien lo pone en práctica?
¿Dónde están estos datos? Legacy, nubes, virtualización, la proliferación de fuentes de datos tan dispares ha vuelto a poner en el centro la Data Architecture.
¿Data Mesh o Data Fabric?
De la misma manera que los equipos de ingeniería de software pasaron de las aplicaciones monolíticas a las arquitecturas de microservicios, se puede decir que Data Mesh es la versión de la plataforma de datos con microservicios. El patrón de arquitectura Data Mesh adopta la ubicuidad de los datos aprovechando un diseño orientado al dominio y al autoservicio. Es evidente que quien conecta a estos dominios y sus activos de datos asociados debe ser una capa de interoperabilidad universal que aplica la misma sintaxis y los mismos estándares de datos, impulsados una gestión proactiva metadatos y datos maestros con el apoyo de un catálogo de datos empresarial y su gobierno. El patrón de diseño de la Data Mesh está compuesto principalmente por 4 componentes: fuentes de datos, infraestructura de datos, conductos de datos orientados al dominio e interoperabilidad. La capa crítica es la capa de interoperabilidad universal, que refleja los estándares agnósticos de dominio, así como la observabilidad, la procedencia, la auditabilidad y la gobernanza.Sobre la auditabilidad tenemos un problema cuando el enfoque es totalmente virtual ya que el regulador puede pedirnos de auditar datos y procesos en el tiempo, en algún lugar tendrá que persistir los datos y por ello en entornos fuertemente regulado al enfoque Data Fabric tiene mas logica.
Data Fabric fomenta una única arquitectura de datos unificada con un conjunto integrado de tecnologías y servicios, diseñado específicamente para ofrecer datos integrados, enriquecidos y de alta calidad, en el momento adecuado, con el método correcto y al consumidor de datos adecuado.
Según Gartner, Data Fabric es una arquitectura y un conjunto de servicios de datos que proporciona una funcionalidad consistente en una variedad de entornos, desde las instalaciones hasta la nube. Data Fabric simplifica e integra la gestión de datos en las instalaciones y en la nube acelerando la transformación digital.
Al menos tres de los pilares estrechamente interconectados identificados por Gartner para el tejido de datos están directamente relacionados con los metadatos:
Catálogo de datos aumentado: un catálogo de información disponible con características distintivas destinadas a apoyar un uso activo de los metadatos que pueda garantizar la máxima eficiencia de los procesos de gestión de datos;
Gráfico de conocimiento semántico: representación gráfica de la semántica y las ontologías de todas las entidades implicadas en la gestión de los activos de datos; obviamente, los componentes básicos representados en este modelo son los metadatos;
Metadatos activos: metadatos útiles que se analizan para identificar oportunidades de tratamiento y uso más fácil y optimizado de los activos de datos: archivos de registro, transacciones, inicio de sesión de usuarios, plan de optimización de consultas.
Cuando el Data Fabric está centrado en los metadatos nos proporciona todas las demás ventajas que son muy importantes a la hora de priorizar las medidas sobre los activos de datos.
Sea Data Fabric o Data Mesh han venido para cambiar completamente el modo de diseñar la arquitectura de datos.
El valor del dato el fulcro de la gestión
Desde la aparición del libro Infonomics de Doug Laney nos hemos dado cuenta que un activo se llama así porque supone un valor. Si antes solo nos centrabamos en la utilidad de este activo ahora nos estamos dando cuenta que tiene un valor monetario.
Si damos un valor a todos los datos, y especialmente a los metadatos, podremos responder a preguntas muy interesantes como ¿Cuáles son los propietarios de datos que gestionan los datos más valiosos para la empresa? ¿Cómo debemos priorizar las acciones de calidad en función del valor que representan estos activos de datos? Si una herramienta de gobernanza tiene el paradigma de Governance by Design, nos permite dar un valor interno (es decir, de la organización) y externo en función de la pérdida de este activo o la venta del mismo. ¿Cuánto valen los datos del cliente para nuestro competidor?
Data Governance y Data Valuation siempre van a ir de la mano.
Las empresas están llenas de datos que no analizan y sobre todo no procesan de forma transversal. Si una compañía aérea solo se centra en analizar sus ventas directa y en el canal y gobierna los dominios de forma vertical está perdiendo mucha información. ¿Qué pasa cuando el número de pasajeros se confrontan con el departamento de operaciones o en el mantenimiento de los aviones? Unas pocas décimas de ahorro en operaciones puede valer tanto como un incremento de pasajeros. Ahorro de costes sin influir sobre el personal y sin renunciar a la seguridad es posible. Los números siempre nos dicen la verdad sea la que encontramos sea la que queremos encontrar (y esto es lamentable).
El problema de los sesgos en la gestión de datos
Desde que tengo Netflix encuentro auténticas perlas de conocimiento. A parte los documentarios sobre Miles Davis o Marcus Miller (uno de los dos quizá sea en Amazon Prime) he visto “Coded Bias” de Joy Buolamwini, una científica informática que descubrió que su cara no era reconocida por un sistema de reconocimiento facial mientras desarrollaba aplicaciones en un laboratorio del departamento de ciencia de la computación de su universidad, a partir de allí descubrió que los datos con los que entrenaron aquel tipo de sistemas eran principalmente de hombres blancos. Esto explicaba por qué el sistema no reconocía su cara afroamericana. El problema no son los datos.
La verdad es que estos sistemas, creados en los años 70, fueron concebidos con el fin de identificar a sospechosos contrastando fotografías contenidas en bases de datos policiales. Incluso hoy en día los sistemas policiales de reconocimiento facial se construyen con bases de datos históricas. No toman en consideración que muchos datos son incompletos, sesgados, reflejo de detenciones ilegales y de racismo policial, lo cual explica, además, que la prevención de delitos mediante esta tecnología posea un alto margen de error.
Y no es todo, la tecnología de reconocimiento facial fue desarrollada gracias al incremento exponencial de caras que se podían obtener desde la Web. Es decir, se hizo sin el consentimiento de las personas. Su uso no fue ético, lo que inhabilitaba desde el comienzo a casi todos estos sistemas. Tengamos claro que la IA sólo nos beneficiará en la medida en que su diseño y uso no perpetúen ni amplifiquen injusticias sociales.
Salta a la vista la sanción que Mercadona tuvo que pagar recientemente por un experimento piloto que desarrolló en 48 tiendas. Según explica la propia compañía, el sistema «aplicaba un filtro tecnológico y una segunda verificación visual establecía que la persona identificada tenía una orden de alejamiento vigente del establecimiento».
Sin embargo, la AEPD ha concluido que se ha vulnerado el Reglamento General de Protección de Datos. En concreto el artículo 6 (Licitud del tratamiento) y el artículo 9 (Tratamiento de categorías especiales de datos personales).¿Cómo diferenciaba el sistema de Mercadona quienes tenían orden judicial? La empresa se basaba en sus propios juicios contra quienes hurtaban y solicitaban al juez que se decretara precisamente esta medida. Quizá una «buena idea», pero donde la AEPD les imputa el hecho de haber empezado antes de realizar la evaluación de impacto. Un informe de impacto donde no se valoraron los riesgos respecto a los propios trabajadores de la empresa y el de los clientes vulnerables como menores, Según la Agencia, se trataban datos biométricos sin base suficiente ni se cumplían los requisitos básicos de interés público objetivo.
Pero el problema de los sesgos no solo aplica al reconocimiento facial sino hasta en la forma de querer interpretar datos. Algunos ejemplos: Nos fijarnos más en cosas que están asociadas con conceptos que usamos mucho o recientemente. En otras palabras, hacemos asociaciones que no siempre son correctas. A veces buscamos patrones e historias en datos dispersos, aun cuando no haya conexión real. Otro ejemplo es simplificar cálculos y probabilidades, lo que se traduce en soluciones fáciles (y la mayoría de las veces erróneas) para problemas complejos.
Si ya nosotros generamos Sesgos todo esto se está transladando a nuestros algoritmos y los resultados serán erroneos: persona de color que Facebook interpreta como “monos” o deduciones de riesgos en entidades financieras basadas en reglas de negocio erronea “si esta mujer esta separada va a tener menos ingresos, etc.”
Gaia X: que no sea una carta a los Reyes Magos
Una de las iniciativas estratégicas más importantes a nivel de gestión de datos es contrastar el poderío de las empresas norteamericanas en el monopolio del cloud. La Comunidad Europea se ha metido las pilas sobre todo porque, incluso China, ha empezado a desarrollar su propia infraestructura en la nube.
El Ministerio de Asuntos Económicos y Transformación Digital, a través de la Secretaría de Estado de Digitalización e Inteligencia Artificial, está impulsando la creación de un hub nacional de Gaia-X, cuyo objetivo es acelerar la capacidad europea en materia de compartición de datos y soberanía digital.
El objetivo de esta iniciativa es desplegar un ecosistema sólido en el ámbito de la compartición de datos, principalmente industriales. Con ello, además, España aspira a liderar espacios de datos en sectores estratégicos como sanidad o turismo.
Este ecosistema debería convertirse en el referente donde las industrias sectoriales acudan para crear comunidad en torno al dato, busquen nuevas soluciones y fomenten la innovación basada en datos e IA en su sector.
Mientras tanto, muchas empresas que habían iniciado la aventura de Gaia-X con mucho entusiasmo parecen haberse desilusionado. Muchos se quejan de la excesiva burocracia de Gaia-X. El proyecto europeo de la nube era cada vez más complejo y amenazaba con abrumar a las empresas. Este 2022 tiene que presentar un cambio de marcha en el proyecto. Los europeos no podemos perder el tren del futuro.
El 2022 Gartner ha señalado estas diferentes TOP Trend Tech
- Generative Artificial Intelligence (AI)
- Data Fabric (de esto hemos hablado ampliamente en este artículo)
- Cloud-Native Platforms (CNPs)
- Autonomic Systems
- Decisión Intelligence (DI)
- Composable Applications
- Hyper Automation
- Privacy-Enhancing Computation (PEC)
- Cybersecurity Mesh
- AI Engineering
- Total Experience (TX)
- Empresa distribuida
Con el aumento de los modelos de trabajo remoto e híbrido, las organizaciones tradicionales centradas en la oficina están evolucionando hacia empresas distribuidas compuestas por trabajadores dispersos geográficamente.
«Esto requiere que los CIOs realicen importantes cambios técnicos y de servicio para ofrecer experiencias de trabajo sin fricción, pero hay otra cara de la moneda: el impacto en los modelos de negocio. Para todas las organizaciones, desde el comercio minorista hasta la educación, su modelo de entrega tiene que configurarse para adoptar los servicios distribuidos” según Gartner.
La pandemia ha sido el gran acelerador de la transformación digital ampliando la brecha entre quien han salido beneficiados y quien se han perdido completamente. La visión de todos los bares y restaurantes vacíos alrededor de Plaza Picasso a Madrid nos ha hecho reflexionar “sirve tener una oficina en el centro de Madrid?”. Cuando Smart Working sea el modelo aplicado al 80% de la semana laboral quien llenará estos lugares? Tiene sentido alquilar unas oficinas de 10 plantas en un rascacielo de Madrid para tenerlas vacías? Quizá dos plantas serán suficientes? El Smart Working ha venido para quedarse.
Conclusiones…
Vuelvo a mi experimento literario de hace unos años citando a mi mismo que es bastante triste…
“Estamos en un entorno inestable, hemos estado pasándolo bien un rato. Pero las cosas han cambiado tenemos que movernos de la zona de la comodidad a la zona de inquietud. Debemos entender que hay nuevos paradigmas y nuevas formas de ver las cosas. Tenemos que actuar y dejar de lloriquear en el recuerdo de qué bonito era esto antes, de que cómodo era tener un sueldo fijo a final de mes, que cómodo era comprarse lo que no podíamos permitirnos, la crisis nos ha librado de muchas esclavitudes y como decía Einstein la única crisis es la crisis de la incompetencia. Incompetencia laboral, ética y política y el fracaso del sistema entendido como “yo existo, gasto y pretendo”.
Ser libre de las nóminas quiere decir asumir riesgos, ser libre de las nóminas quiere decir ser libres de vivir nuestra vida de la forma que más nos complazca y haciendo lo que nos gusta. Con nuestro ritmo y no encauzados en ritmos de otros.
La falsa seguridad que el sistema nos brinda sirve para no hacernos pensar. El miedo al fracaso, el miedo a no poder tirar para adelante nos congela. Y el miedo es el más eficaz inhibidor del cambio. Por esto no cambiamos.
“El dinero es el estiércol del demonio” pero lo necesitamos para sentirnos personas. Esto es absurdo. Nosotros pagamos el precio de la seguridad perdiendo parte de nuestro cerebro.
Pero no queremos una vida frugal. Queremos parecer no ser. Queremos que los demás tengan de nosotros una imagen de éxito. Por ello no vivimos realmente nuestras vidas, buscamos continuamente vivir la vida de otros, compramos, consumimos sin ningún respeto, sin ninguna lógica.”
La inestabilidad es la regla
En lo laboral y en lo profesional. Esto me excita muchísimo. He estado reinventándome por lo menos 5 veces en mi vida. Este 2022 va a ser lo de siempre: “Destination Unknow”.
Disfrutemos de los disruptivos, actuemos contra el miedo, bailemos con el caos y sobre todo aprendamos a gestionar los datos. Sin sesgos, sin prisas pero sin pausas. Los datos son la brújula en el mar de la tempestad que supone el cambio continuo. Feliz 2022.