Es con mucha tristeza que anuncio a toda la Comunidad de DAMA España que he presentado ayer a la presidencia de la asociación mi renuncia en seguir en la junta directiva debido a motivos personales.
Ha sido un periodo intenso y motivador donde hemos estado haciendo todo lo posible para hacer crecer la asociación y la comunidad del Dato en España. Encontramos cenizas y hoy la asociación presenta una cuentas aseada un numero de socios que nos pone entre los lideres mundiales y un numero de certificados sin iguales.
He fracasado en intentar imponer un cambio aun más acelerado y motivador no he sabido trasmitirlo al resto de la junta directiva y me siento completamente demotivado en el seguir dedicando tiempo y ver con impotencia que se toman decisiones que no comparto. O peor aun que no se toman y no se avanza.
He fracasado en intentar crear una junta amplia e integradora pero ha resultado inmanejable por falta de compromiso de algunos.
Por coherencia no puedo seguir, por lo menos no en la actual junta. Seguiré siendo un socio raso pagando su cuota y aportando mi granito de arena cada vez que pueda.
Agradezco todos mis compañeros que han estado conmigo en estos años, aquellos que han aguantado mi determinación y aquellos que no la han soportado. Si alguien se ha sentido ofendido por mi actitud pido disculpas. Siempre he metido vehemencia en todo porque creo en lo que hago. No es un pasatiempo para mi y tengo la mala costumbre de tomarme los compromisos en serio. He aprendido mucho de todos vosotros y sois unos profesionales como la copa de un pino.
Las personas no son imprescindibles lo son los valores, lo es la ética.
DAMA seguirá creciendo y confio plenamente que quien tome el relevo lo sepa hacer mejor yo he metido toda la energía que he podido.
Quedan pendiente muchas cosas que no se han podido abordar:
Profesionalizar la estructura asociativa con un gerente
Redactar e implicarse en un nuevo plan estratégico, un nuevo propósito
Dar el seguimiento que se merecen a nuestros patrocinadores
Redactar un manual de régimen interno que guíe la asociación, donde se ponga de manifiesto que, quien no participa de forma activa no puede estar en una asociación ya que hay un compromiso hacia los socios que tiene que ser prioritario
Re alinearse sin titubear a Dama International manteniendo nuestra particularidad
Estoy seguro que todo esto va a ser una prioridad de este junta directiva o la que siga.
Si es verdad que el 75% de los activos de las empresas Standard & Poor ‘s no son físicos: ¿De qué estamos hablando? ¡De Datos! Qué sería de empresas como Booking, AirBNB, Facebook sin sus datos (y los nuestros) esto es motivo más que suficiente para entender la importancia del Data Management.
Hubo un tiempo en que dijimos a las empresas que tenían que mirar sus datos: nació el business intelligence. Hubo un tiempo en el que quisimos democratizar el uso de los datos y nació el data-driven. Pasado un tiempo, comprendimos que gracias a la virtualización y la nube no es necesario mover los datos y nació Data Virtualization. Algunos me dicen que en el fondo nada ha cambiado. Tenemos una tecnología impresionante, el cloud y el cómputo en la nube disparan el potencial de todo, pero también disparan la entropía.
No estamos en la “transformación digital”, no se trata de algo que llega y al que hay que adaptarse, se trata de hablar de “hábito de evolución digital”. Porque se trata de un proceso continuo no de algo puntual. Un proceso que necesita la Data Governance de la misma forma que necesita otros aspectos relacionados con los datos (Data Quality, Data Analyzing, Data Virtualization, etc.)
Estamos en la era de los Metadatos. Si es verdad que la Inteligencia de Negocio ha cristalizado la estrategia (pasando de “qué” hacer a “como” hacerlo), la Data Virtualization ha permitido liberar los datos de vínculos físicos; la Data Governance va a focalizar sus esfuerzos en los metadatos. Ya no importa la cantidad de datos que podamos tratar ni como lo tratamos. Necesitamos saber que estos datos nos dicen y quien decide que digan algo. Sin Data Governance no existe el Data Management, es la visión de DAMA y la comparto completamente.
Desde hace unos cuantos años me dedico a la gestión de datos, aunque existe un framework referente super importante como el DmBok 2 de DAMA que utilizo a diario, me pareció interesante desarrollar algo muy didáctico para todos aquellos que se acercan al mundo del Data Management. Podríamos decir que este libro es una especie de diccionario alargado para comprender mejor este mundo tan fascinante de los datos.
¡Ahora más que nunca el dato no es una opción es el negocio!
Hablaremos de: Data Literacy, Metadatos, Data Governance, Business Glossary, Data Dictionary, Data Catalog, ETL, ELT, Master Data, Data Lake, Data Warehouse,OLAP, ROLAP, MOLAP, DOLAP y HOLAP, Data Fabric, Data Mesh, Enfoque Declarativo vs Enfoque Procedural, Data Vault, Data Monetization, CDC, Data Virtualization y DmBoK2
Este artículo se ha escrito a 4 manos.. (si se puede decir) de un lado he usado ChatGPT con preguntas muy concretas, del otro he añadido elementos para complementar la información. Imaginarlo como un experimento sobre el argumento del momento y una forma de concretar más el enfoque declarativo en Data Management que es uno de los puntos fuertes de la tecnología de Irion EDM.
El enfoque declarativo se refiere a una forma de expresar un problema o una solución en términos de lo que se desea lograr, en lugar de cómo se desea lograrlo. En lugar de especificar los pasos detallados para resolver un problema, se especifica el resultado deseado.
En programación, el enfoque declarativo se utiliza para escribir código que especifica qué se desea lograr, en lugar de cómo se desea lograrlo. Por ejemplo, en lugar de escribir código que especifica cómo recorrer una lista de elementos y realizar una determinada acción en cada uno de ellos, se escribe código que especifica que se desea realizar esa acción en cada elemento de la lista. El lenguaje de programación se encarga de resolver cómo realizar esa acción.
El enfoque declarativo se utiliza en varios campos, como en bases de datos, en donde los lenguajes declarativos son aquellos que se centran en describir los resultados deseados en una consulta, en lugar de describir cómo se obtienen esos resultados. SQL es un ejemplo de un lenguaje declarativo utilizado en las bases de datos relacionales.
En resumen, enfoque declarativo es una forma de abordar un problema o una solución enfatizando en lo que se quiere lograr en lugar de cómo se quiere lograrlo, permitiendo al sistema o lenguaje de programación encargarse de las tareas de implementación.
Algunos ejemplos de lenguajes de programación declarativos son:
SQL (Structured Query Language): Es un lenguaje declarativo utilizado para acceder y manipular bases de datos relacionales. En lugar de especificar cómo recuperar los datos, se especifica qué datos se desean recuperar mediante consultas.
Prolog: Es un lenguaje de programación lógico declarativo utilizado en inteligencia artificial y programación de sistemas expertos. Permite al programador especificar reglas y hechos, y luego utilizar un motor de inferencia para obtener conclusiones.
Haskell: Es un lenguaje de programación funcional declarativo utilizado para construir sistemas concurrentes y distribuidos. En lugar de especificar cómo se deben realizar las operaciones, se especifican las operaciones que se desean realizar y el lenguaje se encarga de resolver cómo realizarlas.
XSLT: (Extensible Stylesheet Language Transformations) es un lenguaje declarativo utilizado para transformar documentos XML en otro formato, como HTML o PDF. El programador especifica cómo se deben transformar los datos, en lugar de cómo se deben recuperar.
RDF: (Resource Description Framework) es un lenguaje declarativo utilizado para describir recursos y relaciones entre ellos. Es ampliamente utilizado en la web semántica y el enriquecimiento de metadatos.
Enfoque Procedural
El enfoque procedural se refiere a una forma de expresar un problema o una solución en términos de los pasos específicos que deben seguirse para lograr un resultado. En lugar de especificar el resultado deseado, se especifican los pasos detallados para resolver el problema.
En programación, el enfoque procedural se utiliza para escribir código que especifica cómo se deben realizar las tareas, en lugar de qué tareas se deben realizar. Por ejemplo, en lugar de escribir código que especifica que se desea realizar una determinada acción en cada elemento de una lista, se escribe código que especifica cómo recorrer la lista y realizar la acción en cada elemento.
Los lenguajes de programación procedurales son aquellos que siguen un enfoque de programación estructurada, en donde se divide el código en bloques lógicos y se organizan en funciones y procedimientos
Algunos ejemplos de lenguajes de programación procedurales son:
C: Es un lenguaje de programación de alto rendimiento y de bajo nivel, que es ampliamente utilizado para desarrollar sistemas operativos, dispositivos embebidos y aplicaciones de bajo nivel. Es un lenguaje de programación estructurado, con un enfoque en la programación procedural.
Pascal: Es un lenguaje de programación estructurado, desarrollado para la enseñanza de la programación en las universidades. Es ampliamente utilizado para desarrollar aplicaciones de escritorio, juegos y aplicaciones científicas.
Fortran: es un lenguaje de programación procedural desarrollado para cálculo científico y numérico, es utilizado en aplicaciones como simulación de sistemas, modelado de fluidos y análisis estadísticos.
Basic: es un lenguaje de programación procedural muy fácil de aprender para principiantes. Fue diseñado para enseñar a los estudiantes de programación básica
¿Por qué es mejor el enfoque declarativo en Data Management?
El enfoque declarativo en Data Management tiene varias ventajas sobre el enfoque procedural. Algunas de estas ventajas son:
Mayor claridad: El enfoque declarativo permite especificar los resultados deseados de manera clara y concisa, lo que ayuda a reducir el riesgo de errores y aumenta la eficiencia en el manejo de datos.
Mayor flexibilidad: Al especificar los resultados deseados en lugar de los pasos para lograrlos, el enfoque declarativo permite adaptarse fácilmente a cambios en los datos o en los requisitos del sistema.
Mayor escalabilidad: Al permitir la separación entre la especificación de los resultados y su implementación, el enfoque declarativo permite escalar el sistema de manejo de datos sin tener que modificar el código.
Mayor portabilidad: Al separar la especificación de los resultados de su implementación, el enfoque declarativo permite el uso de diferentes sistemas o tecnologías para implementar la especificación.
Mayor eficiencia: Al permitir que el sistema se encargue de implementar la especificación, el enfoque declarativo permite obtener resultados más rápidamente y con menos recursos.
En resumen, el enfoque declarativo en Data Management ofrece una mayor claridad, flexibilidad, escalabilidad, portabilidad y eficiencia en la gestión de datos. Al permitir especificar los resultados deseados en lugar de los pasos para lograrlos, permite una mayor escalabilidad, flexibilidad y portabilidad.
DELT(™) ELT Declarativo
DELT es una de las tecnologías propietarias de Irion. El motor orquesta y sincroniza el plan de procesamiento y control de datos con algoritmos inteligentes, lo que permite a los profesionales de la gestión de datos -que utilizan la plataforma Irion EDM®- trabajar en un entorno autoadaptativo y basado en metadatos.
Las ventajas principales son:
El enfoque declarativo permite al motor DELT™ alcanzar altos niveles de rendimiento al maximizar el paralelismo de las fases de procesamiento.
La arquitectura DELT™ está diseñada para trabajar eficazmente con grandes volúmenes de datos mediante motores orientados a conjuntos.
El ingeniero de datos se encarga de los aspectos semánticos de las soluciones delegando en la plataforma la gestión automática de las estructuras de datos.
La integración de motores con tecnologías heterogéneas, como Query, Script, Rule, R, Python, Masking, Profiling, permite utilizar la herramienta más adecuada para cada situación.
He perdido 3 dias y al final leyendo mucho material incluso en aleman he llegado a la solución.
Lo que no vale en un MacBook 3.1 finales 2007
Primero no es posible hacer <option> – <R>
No es posible hacer un boot desde USB porque no tenia otro mac y los experimentos
con Transmac y diferentes USB no han dado resultado porque el mac no admite boot de USB con la opción <alt>
Solución
Al arrancar este Mac que estaba en alguna parte sin usarse como 4 años empecé a ver el bucle de inicio de sesión: la máquina arranca bien, pero al poner el nombre de usuario y la contraseña, el sistema se cuelga durante unos 20 segundos antes de volver a mostrar la ventana de inicio de sesión. Está claro que algo se ha estropeado, y afortunadamente he podido solucionarlo.
Intenté las soluciones sugeridas – arrancar en modo seguro e iniciar la sesión (seguía teniendo el mismo problema); ejecutar una comprobación del sistema de archivos en modo de usuario único (no se informaba de ningún error); borrar las listas de la ventana de inicio de sesión; y cambiar la contraseña – pero no tuvieron ningún efecto. Pude entrar en la cuenta de administrador temporal que doy a Apple cuando la máquina se envía para el servicio, así que supe que era algo específico de mi cuenta diaria. Pude entrar en el modo de usuario único (manteniendo pulsado Comando-S justo después del sonido de arranque) y examinar el archivo /var/log/system.log. Esto es parte de la naturaleza UNIX subyacente de MacOSX, y fue el único lugar que encontré que daba pistas sobre lo que estaba pasando. Aquí está una parte del archivo de registro que se produce justo después de pulsar retorno en la pantalla de inicio de sesión:
oginwindow[23]: USER_PROCESS: 23 consolecom.apple.launchd[1] (com.apple.UserEventAgent-LoginWindow[86]): Exited: TerminatedReportCrash[106]: Formulating crash report for process lsregister[104]
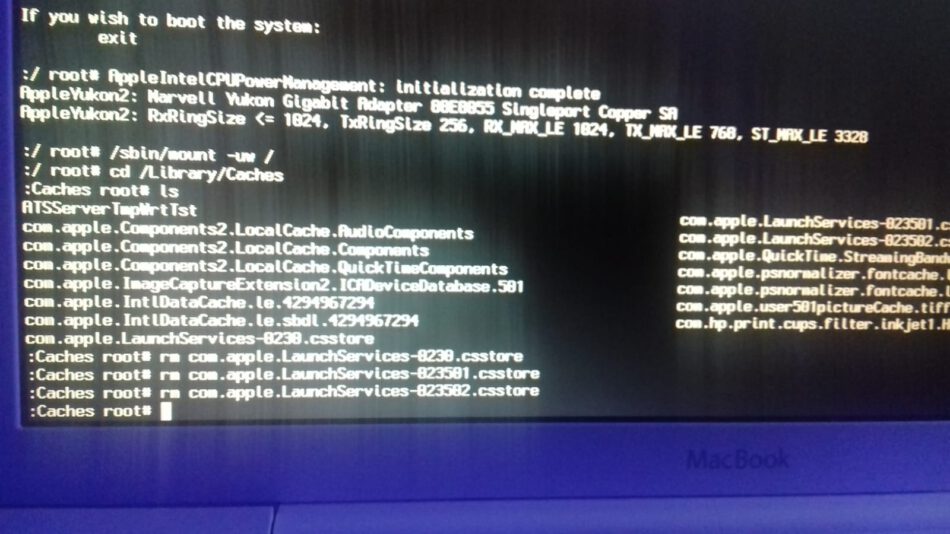
La pista clave está en negrita – el proceso de lsregister está fallando. Encontré una pista para la solución en una publicación del blog de 2003 de un tipo llamado Rick cuando dijo Después de un par de horas de búsqueda, y un poco de suerte (pude conectarme desde otra máquina y ver el registro del sistema informar de los bloqueos), descubrí que la caché de Launch Services estaba dañada, y estaba causando que lsregister fallara. Su publicación estaba relacionada con MacOSX 10.2.6, y desde entonces el nombre del archivo de caché de Launch Services ha cambiado. Lo encontré en el mismo lugar (el directorio /Library/Caches), pero ahora hay más de uno y toman la forma de «com.apple.LaunchServices-023uid.csstore» donde uid varía dependiendo del número de userid apropiado. He eliminado todos los archivos de Launch Services de /Library/Caches, he reiniciado y he podido iniciar la sesión sin problemas. El único efecto secundario fue que la lista de aplicaciones que se lanzan al iniciar la sesión desapareció (la pestaña «Elementos de inicio de sesión» del panel de preferencias de la cuenta) y tuvo que ser reconstruida.
Ahora el Mac funciona aunque no puedo hacer mucho con el…
Recapitulando:
Arrancar con modalidad S
al root#
/sbin/fsck -fy/sbin/mount -uw
Borrar todos los ficheros : «com.apple.LaunchServices-****.csstore” en la carpeta /Library/Caches con RM (foto)
hacer otro
/sbin/fsck -fy
Reiniciar… y ahora el Login Loop ya ha desaparecido…
Algunas reflexiones sobre lo que está pasando dentro de las empresas en los últimos años y como algunas de ellas están enfocando las actividades para el 2022. Algunas de estas reflexiones y retos serán parte del contenido de las mesas redonda de la edición 2022 del Data Management Summit
El fin de año conlleva reflexionar sobre lo que se ha visto en el 2021 para lanzarse al vacío del 2022. El vacío porque normalmente “la vida tiene muchas más fantasías que nosotros” y el mundo empresarial está en una encrucijada muy importante. La pandemia ha supuesto la completa revisión de los procesos de trabajo distribuidos y ha sido un acelerador brutal del mundo de los datos. Hace años ya decía “no existe mi puesto” ahora existe mi lugar dentro de una organización que puede ser incluso virtual. Hace años publiqué un libro titulado “Downshifting, Decrecimiento y Empresa Desestructurada” y leerlo ahora da bastante risa porque muchas de estas “premoniciones” se han materializado.
Todo gira alrededor del Dato…
Y aquella empresa que aún no lo ha entendido está muerta o agonizando. El dato es un activo primordial y da exactamente igual donde se trabaja. En una corporación, en un rascacielo del centro de Madrid o en mi casita de Menorca. Los profesionales se están librando del “curro” y empiezan a vivir de “proyectos”. El mundo del trabajo es dinámico y tus conocimientos de hoy no sirven para lo que viene mañana. Los datos fluyen desde que nos levantamos hasta el último de nuestros días. Muchos de nosotros ni siquiera sabemos cuántos GB generamos cada día. Es más fácil saber cuantos KW gastamos (y las facturas de las eléctricas son bien complicadas) que cuantos datos hemos estado generando, no solo en el trabajo sino en nuestro dia a dia.
Pagar por datos
La famosa frase “si es gratis tu eres el producto y no el cliente” es la que mejor define todo esto. Pero.. ¿Porque la industria, con la excusa de generar mi bienestar se queda prácticamente con todo lo que hago? En el futuro las grandes empresas se encontrarán en el medio de dos gigantes: la ética del dato y las nuevas regulaciones en materia de privacidad. Ahora no ha existido una conciencia global sobre lo que supone la cesión de tus datos pero esto va a cambiar en los próximos años. En el 2022 empezaremos a ver un nuevo fenómeno, las empresas van a ofrecer algo más a cambio, para el uso de tus datos.
Alguien ha empezado a cuestionarse todo esto ya hace un tiempo. En su libro ‘¿Quién controla el futuro?‘, de 2013, Jaron Lanier, un personaje que parece salido de Matrix, se fijó en aquellas personas que, haciendo traducciones, ayudaron a Google a perfeccionar su traductor. Ninguno de ellos vio un euro por su trabajo, evidentemente, pero el buscador se benefició, tanto por el trabajo gratuito como por la mayor visibilidad de sus anuncios.
“Lanier postula que la clase media está cada vez más marginada de la economía en línea. Al convencer a los usuarios de entregar información valiosa sobre sí mismos a cambio de servicios gratuitos, las compañías pueden acumular gran cantidad de datos prácticamente sin costo alguno. Lanier llama a estas empresas «servidores sirena», en alusión a las sirenas de Ulises. En lugar de pagar a cada individuo por su contribución a la base de datos, los servidores sirena concentran la riqueza en manos de los pocos que controlan los centros de datos.” (Fuente Wikipedia)
A parte iniciativas esporádicas como Datum oh Kubik Data más bien relacionada al advertising puro vamos a ver a partir del próximo año muchas empresas que están dispuestas a pagar para que nuestros datos personales y biométricos puedan ser almacenados en sus servidores.
Come cambia el Gobierno del Dato con el nuevo paradigma de la banca abierta
El nuevo entorno del Open Banking está transformando el mundo de la banca debido a un nuevo paradigma en el que los servicios financieros operan en un ecosistema completamente digitalizado. Esto ha conllevado a la completa reinvención de las prácticas y los procesos de los modelos bancarios tradicionales. Un cambio epocal hacia el Open Business y la economía basada en la completa interoperabilidad y las APIs, consecuencia, en parte, de las nuevas regulaciones como PSD2. El cambio de paradigma va a generar nuevas formas de enfocar el gobierno de datos siempre más ligado a la completa trazabilidad de los procesos. No solo roles, definiciones y metadatos sino también procesos materializados en el tiempo para satisfacer las necesidades regulatorias.
¿Cómo acelerar la adopción de Open Linked Data en el mundo de la administración pública?
Si es verdad que Open Data es el movimiento digital al que están adhiriendo paulatinamente gobiernos e instituciones de todo el mundo su adopción sigue siendo difícil. Se lanzan experimentos y portales de datos abiertos pero sin duda el punto de inflexión es el lanzamiento de las iniciativas comunitarias como el Data Governance Act: La UE está trabajando para reforzar diversos mecanismos de intercambio de datos. El objetivo es fomentar la disponibilidad de datos que puedan utilizarse para impulsar aplicaciones y soluciones avanzadas en inteligencia artificial, medicina personalizada, movilidad ecológica, fabricación inteligente y otros muchos ámbitos.
Los Estados miembros han acordado un mandato de negociación sobre una propuesta de Ley de Gobernanza de Datos (DGA). La Ley trataría de establecer mecanismos sólidos para facilitar la reutilización de determinadas categorías de datos protegidos del sector público, aumentar la confianza en los servicios de intermediación de datos y promover el altruismo de datos en toda la UE.
Además, la DGA prohíbe vincular los servicios de intermediación con otros servicios como el almacenamiento en la nube o la analítica empresarial, servicios que están excluidos del ámbito de aplicación de la DGA. Esta medida contra la vinculación pretende evitar que las grandes plataformas tecnológicas creen un bloqueo comercial que pueda perjudicar a los competidores más pequeños.
Si saber cómo se mueven los usuarios en el metro de Madrid puede ser útil para reforzar el servicio público, el mismo dato en mano de cualquier empresa cuyo fin (y faltaría más) es el beneficio propio y de sus accionistas no es la misma cosa. Sin embargo regalamos datos continuamente para ver gatitos y delante de una pandemia no queremos colaborar. Almacenamos continuamente datos obsoletos y sin ningún sentido en una especie de síndrome de diogene digital que no cesa debido que el almacenamiento ya no es un coste tan importante. El problema es que este mismo comportamiento se hace en las empresas que no entienden que es mejor tener pocos datos de calidad que mucho sin ningún sentido, no existe algoritmo que puede ordenar y extraer conclusiones certeras de un dato sin sentido. Por esto los científicos de datos se frustran cada día limpiando datos en vez de entenderlo.
La convergencia de los diferentes modelos de calidad de datos
Sin datos de calidad es imposible tomar decisiones. Existen diferentes modelos y marcos de trabajo, desde DAMA hasta ISO. ¿Cómo medir la calidad de los datos, cómo gestionar los procesos de calidad de forma automática? ¿Cómo evitar las corrupciones de los Data Lakes? ¿Por qué no conseguimos que la calidad de los datos pueda ser un proceso horizontal dentro de la empresa? Esencialmente porque somos perezosos, desde quien atiende las llamadas en un call center hasta quien diseña el proceso de las mismas.
Los procesos de enriquecimiento son el valor de la calidad, pero ¿cómo evitar el fenómeno garbage-in garbage-out? ¿Qué hacer con tantos datos de baja calidad?
Normalmente nos encontramos con estos inconvenientes: datos erróneos que no se corrigen, sino que se vuelven a crear, además los mismos datos son introducidos en diferentes sistemas, registros creados con valores erróneos o ausentes, falta de coincidencia entre los datos creados en diferentes sistemas, lo que hace que se tenga que hacer un trabajo adicional en fases posteriores, datos erróneos creados durante la transacción, lo que provoca una acción posterior de corrección o adición de datos, problemas de latencia entre la creación de los datos maestros y los de las transacciones y su consumo por parte de las aplicaciones de informes y transacciones posteriores
La gran pregunta quizá sea: ¿Cómo convencer a las empresas de que el ciclo de vida de la calidad de los datos incluye la muerte de los mismos? El GDPR lo instruye… pero ¿alguien lo pone en práctica?
¿Dónde están estos datos? Legacy, nubes, virtualización, la proliferación de fuentes de datos tan dispares ha vuelto a poner en el centro la Data Architecture.
¿Data Mesh o Data Fabric?
De la misma manera que los equipos de ingeniería de software pasaron de las aplicaciones monolíticas a las arquitecturas de microservicios, se puede decir que Data Mesh es la versión de la plataforma de datos con microservicios. El patrón de arquitectura Data Mesh adopta la ubicuidad de los datos aprovechando un diseño orientado al dominio y al autoservicio. Es evidente que quien conecta a estos dominios y sus activos de datos asociados debe ser una capa de interoperabilidad universal que aplica la misma sintaxis y los mismos estándares de datos, impulsados una gestión proactiva metadatos y datos maestros con el apoyo de un catálogo de datos empresarial y su gobierno. El patrón de diseño de la Data Mesh está compuesto principalmente por 4 componentes: fuentes de datos, infraestructura de datos, conductos de datos orientados al dominio e interoperabilidad. La capa crítica es la capa de interoperabilidad universal, que refleja los estándares agnósticos de dominio, así como la observabilidad, la procedencia, la auditabilidad y la gobernanza.Sobre la auditabilidad tenemos un problema cuando el enfoque es totalmente virtual ya que el regulador puede pedirnos de auditar datos y procesos en el tiempo, en algún lugar tendrá que persistir los datos y por ello en entornos fuertemente regulado al enfoque Data Fabric tiene mas logica.
Data Fabric fomenta una única arquitectura de datos unificada con un conjunto integrado de tecnologías y servicios, diseñado específicamente para ofrecer datos integrados, enriquecidos y de alta calidad, en el momento adecuado, con el método correcto y al consumidor de datos adecuado.
Según Gartner, Data Fabric es una arquitectura y un conjunto de servicios de datos que proporciona una funcionalidad consistente en una variedad de entornos, desde las instalaciones hasta la nube. Data Fabric simplifica e integra la gestión de datos en las instalaciones y en la nube acelerando la transformación digital.
Al menos tres de los pilares estrechamente interconectados identificados por Gartner para el tejido de datos están directamente relacionados con los metadatos:
Catálogo de datos aumentado: un catálogo de información disponible con características distintivas destinadas a apoyar un uso activo de los metadatos que pueda garantizar la máxima eficiencia de los procesos de gestión de datos;
Gráfico de conocimiento semántico: representación gráfica de la semántica y las ontologías de todas las entidades implicadas en la gestión de los activos de datos; obviamente, los componentes básicos representados en este modelo son los metadatos;
Metadatos activos: metadatos útiles que se analizan para identificar oportunidades de tratamiento y uso más fácil y optimizado de los activos de datos: archivos de registro, transacciones, inicio de sesión de usuarios, plan de optimización de consultas.
Cuando el Data Fabric está centrado en los metadatos nos proporciona todas las demás ventajas que son muy importantes a la hora de priorizar las medidas sobre los activos de datos.
Sea Data Fabric o Data Mesh han venido para cambiar completamente el modo de diseñar la arquitectura de datos.
El valor del dato el fulcro de la gestión
Desde la aparición del libro Infonomics de Doug Laney nos hemos dado cuenta que un activo se llama así porque supone un valor. Si antes solo nos centrabamos en la utilidad de este activo ahora nos estamos dando cuenta que tiene un valor monetario.
Si damos un valor a todos los datos, y especialmente a los metadatos, podremos responder a preguntas muy interesantes como ¿Cuáles son los propietarios de datos que gestionan los datos más valiosos para la empresa? ¿Cómo debemos priorizar las acciones de calidad en función del valor que representan estos activos de datos? Si una herramienta de gobernanza tiene el paradigma de Governance by Design, nos permite dar un valor interno (es decir, de la organización) y externo en función de la pérdida de este activo o la venta del mismo. ¿Cuánto valen los datos del cliente para nuestro competidor?
Data Governance y Data Valuation siempre van a ir de la mano.
Las empresas están llenas de datos que no analizan y sobre todo no procesan de forma transversal. Si una compañía aérea solo se centra en analizar sus ventas directa y en el canal y gobierna los dominios de forma vertical está perdiendo mucha información. ¿Qué pasa cuando el número de pasajeros se confrontan con el departamento de operaciones o en el mantenimiento de los aviones? Unas pocas décimas de ahorro en operaciones puede valer tanto como un incremento de pasajeros. Ahorro de costes sin influir sobre el personal y sin renunciar a la seguridad es posible. Los números siempre nos dicen la verdad sea la que encontramos sea la que queremos encontrar (y esto es lamentable).
El problema de los sesgos en la gestión de datos
Desde que tengo Netflix encuentro auténticas perlas de conocimiento. A parte los documentarios sobre Miles Davis o Marcus Miller (uno de los dos quizá sea en Amazon Prime) he visto “Coded Bias” de Joy Buolamwini, una científica informática que descubrió que su cara no era reconocida por un sistema de reconocimiento facial mientras desarrollaba aplicaciones en un laboratorio del departamento de ciencia de la computación de su universidad, a partir de allí descubrió que los datos con los que entrenaron aquel tipo de sistemas eran principalmente de hombres blancos. Esto explicaba por qué el sistema no reconocía su cara afroamericana. El problema no son los datos.
La verdad es que estos sistemas, creados en los años 70, fueron concebidos con el fin de identificar a sospechosos contrastando fotografías contenidas en bases de datos policiales. Incluso hoy en día los sistemas policiales de reconocimiento facial se construyen con bases de datos históricas. No toman en consideración que muchos datos son incompletos, sesgados, reflejo de detenciones ilegales y de racismo policial, lo cual explica, además, que la prevención de delitos mediante esta tecnología posea un alto margen de error.
Y no es todo, la tecnología de reconocimiento facial fue desarrollada gracias al incremento exponencial de caras que se podían obtener desde la Web. Es decir, se hizo sin el consentimiento de las personas. Su uso no fue ético, lo que inhabilitaba desde el comienzo a casi todos estos sistemas. Tengamos claro que la IA sólo nos beneficiará en la medida en que su diseño y uso no perpetúen ni amplifiquen injusticias sociales.
Salta a la vista la sanción que Mercadona tuvo que pagar recientemente por un experimento piloto que desarrolló en 48 tiendas. Según explica la propia compañía, el sistema «aplicaba un filtro tecnológico y una segunda verificación visual establecía que la persona identificada tenía una orden de alejamiento vigente del establecimiento».
Sin embargo, la AEPD ha concluido que se ha vulnerado el Reglamento General de Protección de Datos. En concreto el artículo 6 (Licitud del tratamiento) y el artículo 9 (Tratamiento de categorías especiales de datos personales).¿Cómo diferenciaba el sistema de Mercadona quienes tenían orden judicial? La empresa se basaba en sus propios juicios contra quienes hurtaban y solicitaban al juez que se decretara precisamente esta medida. Quizá una «buena idea», pero donde la AEPD les imputa el hecho de haber empezado antes de realizar la evaluación de impacto. Un informe de impacto donde no se valoraron los riesgos respecto a los propios trabajadores de la empresa y el de los clientes vulnerables como menores, Según la Agencia, se trataban datos biométricos sin base suficiente ni se cumplían los requisitos básicos de interés público objetivo.
Pero el problema de los sesgos no solo aplica al reconocimiento facial sino hasta en la forma de querer interpretar datos. Algunos ejemplos: Nos fijarnos más en cosas que están asociadas con conceptos que usamos mucho o recientemente. En otras palabras, hacemos asociaciones que no siempre son correctas. A veces buscamos patrones e historias en datos dispersos, aun cuando no haya conexión real. Otro ejemplo es simplificar cálculos y probabilidades, lo que se traduce en soluciones fáciles (y la mayoría de las veces erróneas) para problemas complejos.
Si ya nosotros generamos Sesgos todo esto se está transladando a nuestros algoritmos y los resultados serán erroneos: persona de color que Facebook interpreta como “monos” o deduciones de riesgos en entidades financieras basadas en reglas de negocio erronea “si esta mujer esta separada va a tener menos ingresos, etc.”
Gaia X: que no sea una carta a los Reyes Magos
Una de las iniciativas estratégicas más importantes a nivel de gestión de datos es contrastar el poderío de las empresas norteamericanas en el monopolio del cloud. La Comunidad Europea se ha metido las pilas sobre todo porque, incluso China, ha empezado a desarrollar su propia infraestructura en la nube.
El Ministerio de Asuntos Económicos y Transformación Digital, a través de la Secretaría de Estado de Digitalización e Inteligencia Artificial, está impulsando la creación de un hub nacional de Gaia-X, cuyo objetivo es acelerar la capacidad europea en materia de compartición de datos y soberanía digital.
El objetivo de esta iniciativa es desplegar un ecosistema sólido en el ámbito de la compartición de datos, principalmente industriales. Con ello, además, España aspira a liderar espacios de datos en sectores estratégicos como sanidad o turismo.
Este ecosistema debería convertirse en el referente donde las industrias sectoriales acudan para crear comunidad en torno al dato, busquen nuevas soluciones y fomenten la innovación basada en datos e IA en su sector.
Mientras tanto, muchas empresas que habían iniciado la aventura de Gaia-X con mucho entusiasmo parecen haberse desilusionado. Muchos se quejan de la excesiva burocracia de Gaia-X. El proyecto europeo de la nube era cada vez más complejo y amenazaba con abrumar a las empresas. Este 2022 tiene que presentar un cambio de marcha en el proyecto. Los europeos no podemos perder el tren del futuro.
Data Fabric (de esto hemos hablado ampliamente en este artículo)
Cloud-Native Platforms (CNPs)
Autonomic Systems
Decisión Intelligence (DI)
Composable Applications
Hyper Automation
Privacy-Enhancing Computation (PEC)
Cybersecurity Mesh
AI Engineering
Total Experience (TX)
Empresa distribuida
Con el aumento de los modelos de trabajo remoto e híbrido, las organizaciones tradicionales centradas en la oficina están evolucionando hacia empresas distribuidas compuestas por trabajadores dispersos geográficamente.
«Esto requiere que los CIOs realicen importantes cambios técnicos y de servicio para ofrecer experiencias de trabajo sin fricción, pero hay otra cara de la moneda: el impacto en los modelos de negocio. Para todas las organizaciones, desde el comercio minorista hasta la educación, su modelo de entrega tiene que configurarse para adoptar los servicios distribuidos” según Gartner.
La pandemia ha sido el gran acelerador de la transformación digital ampliando la brecha entre quien han salido beneficiados y quien se han perdido completamente. La visión de todos los bares y restaurantes vacíos alrededor de Plaza Picasso a Madrid nos ha hecho reflexionar “sirve tener una oficina en el centro de Madrid?”. Cuando Smart Working sea el modelo aplicado al 80% de la semana laboral quien llenará estos lugares? Tiene sentido alquilar unas oficinas de 10 plantas en un rascacielo de Madrid para tenerlas vacías? Quizá dos plantas serán suficientes? El Smart Working ha venido para quedarse.
Conclusiones…
Vuelvo a mi experimento literario de hace unos años citando a mi mismo que es bastante triste…
“Estamos en un entorno inestable, hemos estado pasándolo bien un rato. Pero las cosas han cambiado tenemos que movernos de la zona de la comodidad a la zona de inquietud. Debemos entender que hay nuevos paradigmas y nuevas formas de ver las cosas. Tenemos que actuar y dejar de lloriquear en el recuerdo de qué bonito era esto antes, de que cómodo era tener un sueldo fijo a final de mes, que cómodo era comprarse lo que no podíamos permitirnos, la crisis nos ha librado de muchas esclavitudes y como decía Einstein la única crisis es la crisis de la incompetencia. Incompetencia laboral, ética y política y el fracaso del sistema entendido como “yo existo, gasto y pretendo”.
Ser libre de las nóminas quiere decir asumir riesgos, ser libre de las nóminas quiere decir ser libres de vivir nuestra vida de la forma que más nos complazca y haciendo lo que nos gusta. Con nuestro ritmo y no encauzados en ritmos de otros.
La falsa seguridad que el sistema nos brinda sirve para no hacernos pensar. El miedo al fracaso, el miedo a no poder tirar para adelante nos congela. Y el miedo es el más eficaz inhibidor del cambio. Por esto no cambiamos.
“El dinero es el estiércol del demonio” pero lo necesitamos para sentirnos personas. Esto es absurdo. Nosotros pagamos el precio de la seguridad perdiendo parte de nuestro cerebro.
Pero no queremos una vida frugal. Queremos parecer no ser. Queremos que los demás tengan de nosotros una imagen de éxito. Por ello no vivimos realmente nuestras vidas, buscamos continuamente vivir la vida de otros, compramos, consumimos sin ningún respeto, sin ninguna lógica.”
La inestabilidad es la regla
En lo laboral y en lo profesional. Esto me excita muchísimo. He estado reinventándome por lo menos 5 veces en mi vida. Este 2022 va a ser lo de siempre: “Destination Unknow”.
Disfrutemos de los disruptivos, actuemos contra el miedo, bailemos con el caos y sobre todo aprendamos a gestionar los datos. Sin sesgos, sin prisas pero sin pausas. Los datos son la brújula en el mar de la tempestad que supone el cambio continuo. Feliz 2022.
Según Gartner, el Data Fabric es una arquitectura y un conjunto de servicios de datos que proporciona una funcionalidad consistente en una variedad de entornos, desde los locales hasta la nube. Data fabric simplifica e integra la gestión de datos en las instalaciones y en la nube, acelerando la transformación digital. ¿Cómo vamos a convencer a las empresas de que los datos son absolutamente transversales? ¿Cómo podemos realizar una valoración sólida de los datos? ¿Puede el data fabric ayudarnos en esto? ¿Podemos someter los silos de datos?
Gartner define el data fabric como un concepto de diseño que sirve como capa integrada (tejido) de datos y procesos de conexión. Una estructura de datos utiliza el análisis continuo de los activos de metadatos existentes para apoyar el diseño, el despliegue y el uso de datos integrados y reutilizables en todos los entornos, y es una necesidad para las organizaciones impulsadas por los datos: «El enfoque de la estructura de datos puede mejorar los patrones tradicionales de gestión de datos y sustituirlos por un enfoque más receptivo. Ofrece a los gestores de D&A la posibilidad de reducir la variedad de plataformas de gestión de datos integradas y ofrecer flujos de datos interempresariales y oportunidades de integración«.
Por eso es necesario un enfoque «todo en uno», es decir, una plataforma que pueda operar en toda la cadena de datos, desde la ingesta de datos hasta su explotación y visualización.
Un enfoque totalmente virtual (un sistema LDW basado en consultas) tiene la limitación de no poder materializar todos los procesos y, sobre todo, no permite una auditoría completa a lo largo del tiempo y en entornos muy regulados, como la banca y los seguros. El almacén de datos lógicos es un enfoque que puede resolver algún requisito específico, pero no tiene cabida en los procesos estructurados. El regulador no sólo puede preguntarnos cómo se realiza un determinado proceso de extracción y su linaje, también puede querer ver la réplica de un determinado proceso en una fecha concreta para ver todas las transformaciones y todos los procesos que han intervenido.
En contra de las herramientas Patchwork
Normalmente, cuando nos acercamos a una empresa para cualquier tipo de proyecto de datos, nos encontramos con un escenario típicamente fragmentado. Las empresas suelen incorporar herramientas según una lógica más bien comercial del momento histórico de la empresa. Así que es normal encontrar un mosaico de muchas herramientas diferentes: Tendremos fuentes de datos, diferentes almacenes de datos de distintos proveedores, motores analíticos, motores de reporting, cubos OLAP, etc. En el mejor de los casos, pueden proceder del mismo proveedor, pero aún así hay que resolver algunos problemas. ¿Cómo hacemos la automatización del flujo de trabajo? ¿Cómo gestionamos los metadatos? ¿Cómo documentamos los procesos? ¿Qué pasa con la responsabilidad? ¿Cómo respondemos al regulador? Es entonces cuando nos preguntamos a nivel de arquitectura que quizá deberíamos haber hecho de otra manera.
Un enfoque de gestión de datos empresariales (EDM), en el que todos los activos de datos se concentran en una única plataforma, sería la solución óptima. Además, según DAMA, la eliminación de los silos y la plena responsabilidad deberían estar en el centro de cualquier proyecto de datos. ¿Puede el concepto de Data Fabric ser una solución? Según Gartner, los data fabrics reducen el tiempo de diseño de la integración en un 30%, el despliegue en un 30% y el mantenimiento en un 70%, ya que los diseños tecnológicos se basan en la capacidad de utilizar/reutilizar y combinar diferentes estilos de integración de datos. Además, los data fabrics pueden aprovechar las habilidades y tecnologías existentes de los data hubs, data lakes y data warehouses, al tiempo que introducen nuevos enfoques y herramientas para el futuro. En este sentido, aunque un buen enfoque es disponer de una plataforma «todo en uno» con plenas capacidades de interoperabilidad, la implantación de un data fabric no requiere ninguna de las inversiones tecnológicas del cliente.
Según DAMA, el objetivo de la Arquitectura de Datos es ser un puente entre la estrategia comercial y la ejecución de la tecnología, porque la Arquitectura de Datos es más valiosa cuando apoya completamente las necesidades de toda la empresa.
La arquitectura se refiere a una disposición organizada de elementos componentes destinados a optimizar la función, el rendimiento, la viabilidad, el coste y la estética de una estructura o sistema global. Dentro del mundo de los datos mas específicamente, hablamos de arquitectura, cuando, tenemos que lidiar, gestionar, mitigar toda la complejidad de la información.
El término arquitectura se ha adoptado para describir varias facetas del diseño de los sistemas de información. ISO/IEC 42010:2007 Ingeniería de Sistemas y Software – Descripción de la Arquitectura (2011) define la arquitectura como «la organización fundamental de un sistema, encarnado en sus componentes, sus relaciones entre sí y con el medio ambiente, y los principios que rigen su diseño y evolución«.
Multidominio de la Arquitectura
La práctica de la arquitectura se lleva a cabo en diferentes niveles dentro de una organización (empresa, dominio, proyecto, etc.) y con diferentes áreas de enfoque (infraestructura, aplicación y datos).
La disciplina de la Arquitectura Empresarial abarca arquitecturas de dominio, incluyendo negocios, datos, aplicaciones y tecnología. Las prácticas de arquitectura empresarial bien gestionadas ayudan a las organizaciones a comprender el estado actual de sus sistemas, promover el cambio deseable hacia el estado futuro, permitir el cumplimiento de la normativa y mejorar la eficacia. DAMA y el DmBok2 entiende la arquitectura de la información desde las siguentes perspectivas:
Los “Outcomes” de la Arquitectura de Datos, tales como los modelos, definiciones y flujos de datos en varios niveles, usualmente referidos como artefactos de la Arquitectura de Datos
Actividades de la Arquitectura de Datos, para formar, desplegar y cumplir las intenciones de la Arquitectura de Datos
La ontologia de la Arquitectura de Datos y su impacto en la organización, como colaboraciones, mentalidades y habilidades entre los diversos roles que afectan a la Arquitectura de Datos de la empresa
Debido a que la mayoría de las organizaciones tienen más datos de los que las personas individuales pueden comprender, es necesario representar los datos de la organización en diferentes niveles de abstracción para que puedan ser comprendidos y la administración pueda tomar decisiones al respecto
Los artefactos de la arquitectura de datos
Los artefactos de la Arquitectura de Datos incluyen especificaciones utilizadas para describir el estado existente, definir los requisitos de datos, guiar la integración de los datos y controlar los activos de datos tal como se presentan en la estrategia de datos (que se supone alguien ya ha diseñado). La Arquitectura de Datos de una organización se describe mediante las normas que rigen la forma en que se recogen, almacenan, organizan, utilizan y eliminan los datos.
Si el primer punto de cualquier estrategia de datos es entender cuales son los activos actuales de la organización desde la perspectiva del negocio, el segundo punto será entender como nos organizamos, el tercer punto sin duda es el conocimiento de arquitectura técnica (ya no desde la perspectiva de negocio) en su diseño y a partir de una gestión pro-activa de los metadatos.
DAMA recomienda redactar un documento de diseño de la Arquitectura de Datos. Es un modelo formal de datos de la empresa, que contiene nombres de datos, definiciones completas de datos y metadatos, entidades y relaciones conceptuales y lógicas, y reglas de negocio. Se incluyen modelos de datos físicos, pero como producto del modelado y diseño de datos, en lugar de la Arquitectura de Datos.
Los artefactos que crean los arquitectos constituyen valiosos metadatos. Lo ideal sería que los artefactos arquitectónicos se almacenaran y gestionaran en un repositorio de artefactos de arquitectura empresarial.
Las organizaciones con visión de futuro deberían incluir a profesionales de la gestión de datos (por ejemplo, los arquitectos de datos empresariales o los administradores de datos estratégicos) cuando diseñen nuevas ofertas de mercado, porque hoy en día éstas suelen incluir hardware, software y servicios que capturan datos, dependen del acceso a los datos, o ambos.
Desde mi perspectiva, un proceso de gestion de producto siempre necesita el enfoque multiple que solo un equipo multidisciplinario puede facilitar. Una especie de “Comunidad del Anillo” acostumbrada a trabajar en equipo sin dispersion, sin recelos y sin silos de información estancos que son el freno del conocimiento empresarial.
Según el DMBok2, el objetivo de la Arquitectura de Datos es ser un puente entre la estrategia comercial y la ejecución de la tecnología. Como parte de la Arquitectura Empresarial, los Arquitectos de Datos:
Preparar estratégicamente a las organizaciones para hacer evolucionar rápidamente sus productos, servicios y datos a fin de aprovechar las oportunidades comerciales inherentes a las tecnologías emergentes
Traducir las necesidades comerciales en requisitos de datos y sistemas para que los procesos tienen sistemáticamente los datos que requieren
Gestionar la entrega de datos e información compleja en toda la empresa Facilitar la alineación entre el negocio y la TI
Actuar como agentes de cambio, transformación y agilidad
Estos impulsores de negocios deberían influir en las medidas del valor de la Arquitectura de Datos.
Los arquitectos de datos crean y mantienen el conocimiento organizacional sobre los datos y los sistemas a través de los cuales se mueven. Este conocimiento permite a una organización gestionar sus datos como un activo y aumentar el valor que obtiene de sus datos mediante la identificación de oportunidades para el uso de los datos, la reducción de costos y la mitigación de riesgos.
A estas alturas del año es el momento de empezar a pensar en el http://datamanagementsummit.org de este año. Uno de los momentos mas interesante es sin duda cuando los expertos se sientan alrededor de «un argumento» estas son las mesas redonda que he pensado para la edición española que se hará el 20-21 de Octubre y la Italiana que se realizará el 23-24 de Noviembre.
Gobierno de datos, gestión del cambio y mentalidad ágil para alcanzar los objetivos de Quick Wins
Si seguimos el enfoque DAMA-I y su marco de referencia DmBok2, el Gobierno de Datos es el núcleo de la Gestión de Datos. La implementación de un proceso de Gobierno de Datos requiere una importante gestión del cambio. ¿Cuántas herramientas pueden ser útiles para crear una mentalidad ágil en las empresas? Si es cierto que la elección de la herramienta para el gobierno de datos es el último paso, ¿cómo motivar a los equipos y fomentar los QuickWins que pueden ayudar a la implementación?
Data Intelligence y Green Data: la nueva moda en la gestión de datos
La inteligencia de datos es la combinación de: Analítica avanzada, reconocimiento de imágenes, realidad aumentada, inteligencia artificial, aprendizaje automático, aprendizaje profundo, VMI y PIM. Green data es el diseño y gestión de la fase de crecimiento de los datos como si se tratara de un vegetal, desde la siembra y la plantación hasta la recogida de sus frutos.
Data Fabric una forma fácil de llegar a la Valuación de Datos
Según Gartner, Data Fabric es una arquitectura y un conjunto de servicios de datos que proporciona una funcionalidad coherente en diversos entornos, desde los locales hasta la nube. Data Fabric simplifica e integra la gestión de datos en las instalaciones y en la nube acelerando la transformación digital. ¿Cómo vamos a convencer a las empresas de que los datos son absolutamente transversales? ¿Cómo podemos realizar una sólida valoración de los datos? ¿Puede Data Fabric ayudarnos en esto?
Analítica avanzada: No más ETL, no más almacenes de datos para el nuevo esfuerzo de conocimiento en tiempo real
La analítica ha cambiado, las empresas no la utilizan mirando al pasado, sino mirando al futuro. La cultura del análisis ha matado definitivamente al reporting. La toma de decisiones necesita los datos de hoy y de mañana. ETL, ELT, ET(L), Virtualización de Datos y sobre todo DataLake y la Nube han cambiado la arquitectura de las empresas.
Una de las cosas más fascinante que he encontrado dentro de IRION es sin duda el enfoque Declarativo. Es algo tan sencillo y tan potente. En años de Data Management siempre me he topado con problemáticas de gestión de datos. De procesos de extracción, de manos en la masa de datos, proyectos interminables, lentos, procesos de cargas sin fin, etc.
Este artículo es fruto de mi afán de entender las cosas bien. Quería aclararme bien mi storytelling para la introducción de Irion en el mercado Español. Lo más bonito de mi trabajo es el aprendizaje que cada día los diferentes clientes y proyectos me aportan. Pero vamos con orden ¿que es un enfoque declarativo? Volviendo a mis antiguos apuntes de programación “Los programas se pueden clasificar por el paradigma del lenguaje que se use para producirlos. Los principales paradigmas son: imperativos, declarativos y orientación a objetos.” Sin ir mucho más lejos, SQL es declarativo, lanzar una query quiere decir quiero obtener un resultado concreto no me interesa saber de qué forma lo haces a nivel interno ya que los programas que usan un lenguaje declarativo especifican las propiedades que la salida debe conocer y no especifican cualquier detalle de implementación. El ejemplo más típico es el de la Paella, si voy a comer una a un restaurante simplemente pido “una paella”, no comunicó al camarero que quiero que se vayan sofriendo pollo y conejo con algo de ajo, aceite y romero, para luego poner las verduras, para luego poner el tomate el pimienton, todo ello con el caldo para luego verter el arroz… No somos expertos de cualquier cosa (aunque mi paella debido a los años de vida en Valencia no está nada mal por ser italiano) y cuando no llegamos a algo o no sabemos hacer algo delegamos en trabajo en alguien que sepa hacerlo mejor, más rápido y más bueno (sobre todo si de paella se trata).
Pero nosotros nos ocupamos de datos, muchos datos, estructurados, no estructurados en una gran cantidad de fuentes externas, de proveniencia histórica o reciente. Datos que tenemos que Gobernar y tener bien aseados a nivel de calidad. Datos que tenemos que rectificar, reconciliar, mantener historicizados. Datos que tenemos que “documentar” porque es el regulador que nos lo impone y de ellos tenemos que tener una trazabilidad total y el proceso tiene que ser repetible. Hasta ayer, hoy todo esto se nos hacía muy complejo, estos datos tenían que limpiarse, adaptarse, extraerse, copiarse, y por ello existen diferentes enfoques el más histórico y utilizado ha sido el ETL.
ETL Extract Transform Load
Ya hemos hablado largo y tendido de todas las problemáticas de los procesos ETL en otro artículo. Justo para introducir el tema, ETL son las siglas de Extract-Transform-Load. El término ETL describe el proceso de mover datos y hacer manipulaciones con ellos. Las herramientas ETL suelen tener funciones de conexión a múltiples plataformas de datos y aplican transformaciones a los datos en la memoria. Después, presumiblemente, el resultado se registra en algún lugar. Los algoritmos ETL también pueden escribirse en la mayoría de los lenguajes de programación modernos, pero muchas organizaciones consideran que esta opción es menos preferible debido a la sobrecarga que supone escribir el código desde cero y a la complejidad desconocida del soporte posterior.
Llegó un momento en que nos dimos cuenta de era inutil repetir estos procesos de cargas, y las nuevas tecnologías y los nuevos enfoques nos han brindando el CDC (Change Data Capture)
CDC Change Data Capture
CDC es uno de los patrones ETL para copiar datos. Se utiliza para auditar cada cambio en un registro: ya sea que cambie alguno de los valores o que se elimine un registro. Antiguamente, este patrón se implementa con herramientas ETL comparando la última copia de los datos con el origen o comprobando la marca de tiempo de actualización del registro de origen. El rendimiento era pésimo y había una enorme posibilidad de perder algunas de las actualizaciones. Las herramientas de CDC han cambiado las cosas drásticamente, utilizan registros de transacciones para rastrear los cambios, por lo que ningún cambio pasa desapercibido, y ni siquiera afecta al rendimiento de la base de datos de origen. Hay dos métodos diferentes para detectar y recoger los cambios: el data el versionado, que evalúa las columnas que identifican las filas que han cambiado (por ejemplo, las columnas last-update- columnas de fecha y hora, columnas de número de versión, columnas de indicador de estado), o mediante lectura de registros que documentan los cambios y permiten replicarlos en sistemas secundarios. El CDC nos brindó muchas mejoras sobre todo en términos prestacionales, herramienta como Qlik ha hecho de CDC un mantra sobre todo cuando su producto ha querido salir del mundo OLAP. Pero… Llegó la nube y lo cambió todo, almacenamiento y cómputo de alta disponibilidad han creado un nuevo escenario.
ELT Cargamos primero…
El enfoque ETL fue una vez necesario debido a los altos costos de la computación y el almacenamiento en las instalaciones. Con el rápido crecimiento de los almacenes de datos basados en la nube y la caída en picado de los costos de la computación y el almacenamiento basados en la nube, hay pocas razones para seguir haciendo la transformación antes de la carga en el destino final. De hecho, dar la vuelta a los dos permite a los analistas hacer un mejor trabajo de forma autónoma.
En pocas palabras ahora los analistas pueden cargar los datos antes de transformarlos, no tienen que determinar de antemano exactamente qué conocimientos quieren generar antes de decidir el esquema exacto que necesitan obtener y esta es una gran ventaja.
En su lugar, los datos de la fuente subyacente se replican directamente en un almacén de datos, que comprende una «única fuente de verdad». Los analistas pueden entonces realizar transformaciones en los datos según sea necesario. Los analistas siempre podrán volver a los datos originales y no sufrirán transformaciones que puedan haber comprometido la integridad de los datos. Esto hace que el proceso de inteligencia de negocio sea incomparablemente más flexible y seguro.
DELT(™)
Delt es una de las tecnologías propietarias de IRION. El motor orquesta y sincroniza el plan de procesamiento y control de datos con algoritmos inteligentes, lo que permite a los profesionales de la gestión de datos -que utilizan la plataforma Irion EDM®- trabajar en un entorno autoadaptativo y basado en metadatos.
Las ventajas principales son:
El enfoque declarativo permite al motor DELT™ alcanzar altos niveles de rendimiento al maximizar el paralelismo de las fases de procesamiento.
la arquitectura DELT™ está diseñada para trabajar eficazmente con grandes volúmenes de datos mediante motores orientados a conjuntos.
El ingeniero de datos se encarga de los aspectos semánticos de las soluciones delegando en la plataforma la gestión automática de las estructuras de datos.
la integración de motores con tecnologías heterogéneas, como Query, Script, Rule, R, Python, Masking, Profiling, permite utilizar la herramienta más adecuada para cada situación.
Un enfoque declarativo permite concentrarse en lo que se quiere obtener. Esto es lo que importa.
Hoy inicia una nueva aventura, se abre una nueva etapa profesional en Irion. En particular quiero agradecer Giovanni Scavino, Alberto Scavino por la confianza y Egle Romagnolli por el soporte. Me uno a un equipo de alto nivel con 150 profesionales del #DataManagement #Irion#EDM es una plataforma abierta, escalable y eficiente basada en el innovador y disruptivo paradigma «declarativo» para implementar y gestionar las fases de un proceso de #DataManagement. Proporciona toda la funcionalidad necesaria de principio a fin en una arquitectura modular preparada para #DataFabric. Irion EDM está totalmente orientado a los #metadatos gracias a su enfoque declarativo, puede delegar la ejecución de todos los procesos. Basado en #SQL es intuitivo fácil de configurar, incluso para no técnicos.











![Como solventar el problema del loop login en Mac OS X en un MacBook 3.1 antiguo que no tiene modalidad R [solucionado]](http://micheleiurillo.es/wp-content/uploads/2022/08/WhatsApp-Image-2022-08-22-at-12.27.28-PM-672x372.jpeg)